Sign up for the QMED & MD+DI Daily newsletter.
Designing for Software System Integration: Architecture Makes the Difference
Medical Device & Diagnostic Industry MagazineMDDI Article IndexOriginally Published May 2000COVER STORYThe correct choice of a software architecture and its supporting operating system facilitates development and clears a path to the marketplace.
May 1, 2000
49 Min Read
.svg?width=850&auto=webp&quality=95&format=jpg&disable=upscale "Designing for Software System Integration: Architecture Makes the Difference")
Medical Device & Diagnostic Industry Magazine
MDDI Article Index
Originally Published May 2000
COVER STORY
The correct choice of a software architecture and its supporting operating system facilitates development and clears a path to the marketplace.
Today's software developers are faced with a serious challenge—how to produce a safe and reliable product in the shortest possible time frame. This is not a new problem; it has simply been exaggerated in recent years by pressures from the marketplace, and the medical device manufacturing industry certainly is not immune to those pressures. Many solutions have been sought by manufacturers, including throwing large budgets into software development tools and manpower. In some cases these approaches have worked, but often they have not.
This article shows that the software system architecture, coupled with the proper choice of an operating system (OS) that supports this architecture, is the key to faster development and more-reliable system operation in the field. Throughout the article, references to the word process generally refer to the concept of a software process (an instance of an executing program) rather than a medical process or treatment.
In addition, the term system will refer to a medium or large embedded system; typical examples might be a patient-monitoring system, a dialysis machine, or an MRI scanner. While many of the techniques presented here lend themselves well to systems of any size, several could not be applied to a smaller system such as might be implemented on an 8051 microcontroller. The hypothetical software example presented is designed with the idea that it will likely change in the future—few products today are only released once and never revised. Thus, the architecture chosen for the system lends itself well to future modifications.
COMPONENTIZATION
To achieve faster integration, manufacturers must break their system problem into small components that allow for integration. Among its many advantages, componentization
Breaks the problem into logical, easy-to-understand entities.
Permits the abstraction of complex layers, such as hardware, into simplified interfaces.
Permits rapid design through parallel development efforts.
Facilitates testing, since components can be tested in isolation.
Permits the reuse of developed components between projects.
While the advantages of breaking a system into components may be obvious, the proper software architecture to represent these components, and the communication mechanism between them, are not.
SYSTEM ARCHITECTURE
When designing a system, consideration must first be given to the medical task the system is intended to perform and the processes required to accomplish it. This information will dictate what types of hardware are required (e.g., what types of sensors), and what safety requirements will be placed on the system. This portion of the development forms the overall specification phase of the project and, though important, is beyond the scope of this paper. At some point during this decision-making process, however, design of the software system must begin. This software design should begin as early as possible so that the software's impact on the development of the overall system can be understood. For example, a manufacturer often selects hardware from among similar devices that will not have a bearing on the medical process or system cost. If the hardware is chosen blindly (i.e., without software consideration), however, equipment might be purchased that could considerably lengthen the software development time.
The first element to be considered in designing a software system is the choice of a proper software architecture—this element has serious ramifications on how easily, and how quickly, the system will be integrated later. While this decision should be based on factors such as easing system complexity and maximizing system responsiveness, it is often based solely on the prior experiences of the designers and the assumptions they hold regarding the weaknesses of various architectures. To design a system properly, however, each type of architecture must be looked at fully to understand its real strengths and weaknesses, and how it might fit with the system being designed.
Three basic software architectures exist for a medical device manufacturer's consideration: single-process, control-loop architecture; single-process, threaded architecture; and multiple-process architecture. Each is presented below and will be examined for its advantages and disadvantages. All of the architecture explanations assume the presence of an underlying OS and its associated system services.
Single-Process, Control-Loop. The single-process, control-loop architecture is probably the most well known method of system design. In this approach, the system consists of one large process that is broken down into logical subroutines and coordinated using one large control loop. During the execution of the control loop, events that have occurred since the last loop cycle are examined and processed by calling the appropriate set of subroutines. In addition to providing a logical breakdown of the system, this architecture offers several other advantages:
The system is easy to break into logical work units (subroutines) that can be developed and tested independently through the use of dummy code; this permits the system to be built up as development continues.
Data can be localized to a particular subroutine or easily shared between the subroutines as needed.
By executing as one large, single program, only subroutine call time needs to be considered, and this can generally (though not always) be treated as insignificant.
Given these advantages, this method would appear to be the ideal architectural choice, and in the case of a simple, small system, this is often true. Unfortunately, few systems today are either simple or small. When a system becomes even moderately complex, many problems can occur when attempting to integrate the components from this architecture model, even though each component may have worked perfectly during isolated development and testing. Difficulties include the following:
Programmers need to be aware of all global variables used in the system to avoid an inadvertent name conflict and the resulting data corruption and system unpredictability.
Since all subroutines share the same heap and stack space, referencing an improperly set pointer or an out-of-bounds array index can cause data corruption, system instability, or the complete failure of the control program. This is a problem that exists in all processes; it is magnified in systems using this type of design, however, due to the large number of components involved and the potential interactions among them. Additionally, the entire operation of the system depends solely on the proper operation of this single process.
With the system design of one large loop, the timing of the loop is dependent on the number of subroutines called and the time it takes for each subroutine to execute. The addition of each new code module during integration increases the time required for the system to complete the control loop, often beyond the tolerance of critical timing areas within the system (e.g., servicing a hardware device). This problem can be somewhat alleviated by periodically testing for conditions that affect time-dependent code and then invoking the critical elements when necessary. Nevertheless, the method still has numerous problems since it requires all programmers to have knowledge of the entire system to be able to lace their code with the appropriate tests, and it does not eliminate the window of vulnerability that exists between each test.
Single-Process, Threaded. Under the single-process, threaded architectural model, the system is coded as one large process with multiple threaded paths of execution throughout its code base. Threads execute independently of each other, and each thread has the ability to block while waiting for an event to occur without interfering with the execution of other threads. Thread execution scheduling is the concern of the OS, not the programmer.
In addition to the advantages enjoyed by the single-process control loop, threaded processes offer the following advantages:
Programmers do not need to be aware of time-critical operations other than their own—any thread can wait on an event (such as a timer) without constant manual checking, which is necessary in the single-process, control-loop model. This permits better use of the processor and eliminates the window of vulnerability that occurs between manual checks.
In addition to localizing data to a subroutine, data can also be localized to the thread because each thread is assigned a separate stack. Data can still be easily shared among threads since they share a common heap.
If supported by the OS, threads may be prioritized so that preemptive scheduling can occur.
Thread switches are fairly fast, though not as fast as a subroutine call.
On the other hand, threads do present their own problems. Like single-process control loops, thread-based architectures often fail during integration even though each component may have tested perfectly. These problems can often be attributed to the following factors:
While the stack space is separate for each thread, the heap space is not. The problems remain the same as in single-process control loops—global name conflicts, improper pointer references or array indexes, and so forth.
Data concurrency issues can arise in the heap space; because the OS can switch the thread being executed at any time, and because any thread can access the shared heap, care must be taken to ensure that conflicts do not occur during multiple-step data operations. The real problem is that programmers may fail to consider this possibility because they have never dealt with it before. Additionally, the program is difficult to debug since it is time and event dependent, making problems difficult to reproduce. Some OS implementations permit the user to turn off thread switching in critical sections to avoid concurrency issues, but this solution often creates new problems with regard to latency and real-time response.
Multiple-Process. Under the multiple-process model the system is coded as a series of separate, cooperating processes. Like threads, processes execute independently of each other, with each thread having the ability to block when waiting for a specific event to occur without interfering with the execution of other processes in the system. In fact, a process is defined as being made up of one or more threads, though support for more than a single thread is OS dependent. Although many items are similar, what makes this model different from the single-process, multiple-thread architecture is the protection that it provides: the memory space for a process is completely separate from that of all other processes.
In addition to the advantages enjoyed by single-process models, multiple-process models have the following advantages:
System complexity can be more easily handled; complex systems can be broken up into a team of cooperating processes that share resources.
A process is the equivalent of a black box—an encapsulated processing component with defined access points. This design would appear to make for easier testing and integration, as there should be no inadvertent interactions with other processes in the system; this is not always the case, however, since it involves both cpu and OS support for a memory management unit (MMU). Lack of this support can have a significant impact on both system integration time and reliability.
Programming teams can develop and test one software subsystem even if related subsystems are not working. An example would be in a situation where one team is working on module A and another team on module B. The two modules will interact closely with each other in the final product, but since every module or group of modules can run as an independent process, the first team can start to write, test, and debug module A without having to wait for the second team to start on module B. All the two teams have to do is decide on the form of data the modules will share. A simple test harness can then replace module B, so the first team can test if module A correctly interacts with the still-unwritten module.
Depending on the OS, it may be possible to start and stop processes dynamically. This gives the system more flexibility, since it can be configured at the start of runtime and, if necessary, during operation. If may also permit field upgrades without the need to restart the runtime system—the process can simply be replaced and restarted.
Developers do not have to worry about compile options that are specific to program memory; offsets are either assumed to be at a common base or are fixed at link time.
Of course, multiple-process models are not without potential problems:
In addition to switching between threads, there is also the need for context switching between processes; this is a more complex operation and potentially has a higher overhead cost.
Within the process, the heap space remains the same for all threads. This can lead to problems such as global name conflicts, improper pointer or array index references, and data concurrency issues.
INTERPROCESS COMMUNICATION
The next issue that must be considered in designing a software architecture model is to determine how to communicate between the processes—or, more precisely, between threads in different processes, since a process comprises one or more threads. For purposes of clarity, however, this article limits processes to single-thread entities.
A common mistake is to assume that any OS will provide an adequate method of interprocess communication (IPC) for the task at hand, leading developers to choose their OS based on other factors, such as development tools. While these other factors are important to consider, designers need to remember that the IPC mechanisms provided by an OS must meet the requirements of the task at hand; the use of an inadequate mechanism may force the developer into design choices that can compromise system function or integrity during operation.
Signals. Signals are perhaps the simplest form of IPC. Limited to indicating only the occurrence of an event (signals carry no data payload), a signal acts as a software interrupt to the receiving process, causing it to execute special signal-handler code the next time that process is scheduled to execute. This final point is important: developers may assume that the delivery of the signal is sufficient for that process to be next to execute, but that is incorrect. Process execution is dependent on the scheduling algorithm of the OS, not the delivery of the signal.
The primary problem with signals is that they work as designed—as asynchronous interrupts. This limits their usefulness for general IPC, since one never knows when they will execute and must take steps to prevent data concurrency problems. Additionally, an OS may have a window of vulnerability between the entry point of the signal handler and the rearming of the signal; if the same signal is triggered during this time period, the process will be killed. Signals are useful, however, when a software interrupt is necessary for proper system operation; typical examples of this are user-initiated interrupts (typically via the keyboard) and notification of a math error.
Pipes. A pipe is a one-way, byte-oriented, FIFO communication channel between two processes; multiple pipes can be used if bidirectional communication is required. The problem with pipes is primarily one of misconception: it is often assumed that pipes are completely asynchronous. In reality, pipes can block either the reader or the writer. Writing to a pipe is asynchronous until the pipe is filled; at that point the writing process will block until there is room for more data. Similarly, the reading process will block if there are no data in the pipe to read. If the developer remembers this and realizes that pipes require an intermediate copy of the data to be kept, pipes are a useful IPC mechanism.
Queues. The use of queues is probably one of the most well known methods of IPC today. The concept is simple: each process creates one or more queues into which other processes can asynchronously write messages. Unlike pipes, however, queues are not simply FIFO byte streams:
Queues have an internal structure where the basic component is a message.
Message length can be arbitrary (subject to OS-imposed limits).
Queues can have multiple writers.
If the query is supported by the OS, developers can examine the queue state (number of messages, etc.).
If supported by the OS, messages can be delivered in priority order.
On the other hand, queues have three primary disadvantages:
The size of the message cannot exceed the maximum length imposed by the OS.
A queue has a defined length that cannot be exceeded.
Depending on the OS, placing a message on a queue could create an intermediate copy of that message.
Queues can be implemented either internal or external to the kernel. Implementing the queue as an external process, however, offers an interesting advantage to developers: it permits them to replace the queuing mechanism with one customized for a specific task. An example would be a developer who needs to simultaneously notify several processes of a particular event. While he or she could send individual messages to each queue, it would be faster to send one message to a queue mechanism that internally distributes the message to the multiple queues— keeping only one copy of the original message and creating links to the message in each queue.
Shared Memory. Shared memory claims the distinction of being one of the fastest mechanisms to share data between processes. To use shared memory, a process defines a specific region of memory for use. Specification is defined by starting location and size. Other processes may then use this region by either directly receiving a pointer to this memory region or by using an indirect reference provided by the OS (such as a file system name) to eventually receive a pointer to the region. Shared memory provides the following advantages:
Fast access—by attaching to a shared memory region, a process effectively increases its addressable memory space. Once this is done, the process can access the shared memory area simply by using a pointer into that region.
If the OS uses the processor's MMU to protect the shared memory region, then improper references to this region by a process will not corrupt other parts of the system. Shared memory regions generally have a predefined size and will not grow beyond set limits.
Depending on the OS implementation of shared memory, access to a shared memory region may be restricted to those processes with appropriate permission.
The disadvantages of shared memory include the following:
Data concurrency problems can occur if multiple processes attempt to access identical areas of the shared memory region simultaneously. To avoid this contention, data synchronization primitives must be used, typically either a mutex or a semaphore. Implementation of the data synchronization primitives is OS dependent and can have a severe impact on the IPC performance using shared memory. If these primitives are slow, shared memory may be slower than other types of IPC.
Shared memory is local to the machine where the memory resides; it is impossible to access it across a network.
When a process has write permission on a shared memory region, it may write anywhere within that region; this can result in extensive data corruption if the area written to was not the intended target. For example, if the overwritten data controlled the breaths-per-minute rate of a ventilator, the consequences could be severe.
Synchronous Messaging. In addition to being one of the most powerful forms of IPC, synchronous messaging may be the most misunderstood. With synchronous messaging, processes communicate directly with each other via messages; accomplishing this task, however, requires that the processes synchronize with each other (i.e., both processes must be prepared for data transfer) before the transfer of data actually occurs. Only in an ideal case, however, would both processes be ready to transfer data at exactly the same moment, requiring either the sending or receiving process (depending on which is ready first) to block until the other process is also ready, at which point the data transfer occurs. This does not end the transaction, however, since the receiving process may wish to formulate a reply to the sender, so the sending process continues to remain blocked while the receiver processes the message. When that is complete, the receiving process replies to the sender (optionally with data), freeing the sending process to continue execution.
Depending on the OS, data transfer can take one of two forms: either the data is copied directly to a buffer in the receiving process, or a pointer is passed to the data in the memory space of the sending process. The second approach is possible because the first task is blocked and cannot access the data. For the purposes of this article, however, only the data-copy approach will be considered, because it does not permit potentially dangerous random access to the memory space of another process.
When first evaluating synchronized messaging, many developers dismiss it out of hand because of what they perceive as problems in its use. Arguments against synchronized messaging are generally made along three lines: message passing incurs more overhead than other forms of IPC, bidirectional communications are impossible due to deadlock, and the blocking of the sending process presents numerous insurmountable design problems. While these problems are possible given an inappropriate system architecture or an improper implementation of the IPC mechanism by an OS, none of these arguments should deter developers from at least evaluating synchronized messaging in relation to their design. In many cases, using the proper design techniques for synchronized messaging—in combination with other appropriate IPC mechanisms—can lead to easier implementation, better performance, and increased system reliability.
The first argument against synchronized messaging is that it is too slow—not only must the data be copied between processes, but the OS must also context switch between the processes. Both statements are true, though they fail to consider the impact of the OS itself. For example, at least one operating system, running on a Pentium 233-MHz processor, can perform a full context switch in 1 microsecond—faster than some operating systems can thread switch. Message transfer time can be equally fast, transferring a 20-byte message (a fairly typical message size) in an additional 1 microsecond. In a single transaction between two processes consisting of a 20-byte message and a 20-byte reply, 4 microseconds of overhead has been incurred—generally an insignificant time period in the overall scope of system timing requirements (two context switches would be involved here, the first from the sending to the receiving process, the second switching back to resume work). For small messages, message copying can actually be more efficient than a shared memory operation, depending on the OS. Additionally, each process has its own copy of the data to process, eliminating the potential contention and delay that can occur when using a single shared copy.
Does this mean message passing is always the best approach? Certainly not in the case when large amounts of data are involved—for example, a megabyte of graphics data—since copying all of this data would consume too much time. In this case, shared memory makes more sense. While the passing of large amounts of data may be prohibitive in many processes, a valuable alternative may be sending a message containing an offset that points to the data location in shared memory.
The second argument against synchronized messaging involves the problem of bidirectional communication: if two processes send a message to each other, the result will be deadlock. This does not mean that bidirectional communication is impossible; it simply means that it must be designed for. Solutions such as message timeout and token-passing schemes are possible, although this problem can also be solved using the IPC architecture itself.
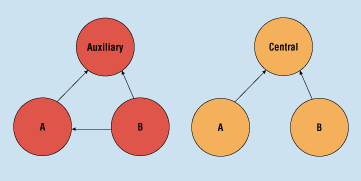
Figure 1. Using auxiliary and central processes to eliminate deadlock.
The simplest method of solving the problem is to involve additional processes, as shown in Figure 1. In the auxiliary process model in the left diagram, process B has a second process associated with it, permitting process A to send its messages to the auxiliary process, and process B to send its messages directly to A. When process B wishes to examine its messages, it sends a message to its auxiliary process to retrieve the messages. No possibility of deadlock exists, as no two processes send directly to each other. Note that the auxiliary process never sends directly to Process B; this could lead to a circular deadlock.
The above solution is cumbersome, however, since the designer must keep track of which processes have an auxiliary task and which do not. Another solution would be to give every process an auxiliary task, but there is an even simpler method. A single task can be used where all processes can send and receive their own messages. This method is the central model shown on the right side of Figure 1. If this type of functionality sounds familiar, it should—it is a queuing process. While this solution (involving the use of a third process) does incur extra overhead, it is versatile and very fast.
The last common argument against synchronized messaging involves the difficulty of designing a system around a mechanism that causes the sending process to block. More accurately, though, the argument should be stated as the difficulty of applying traditional designs in a synchronized messaging environment. By looking at the problem differently, however, possible solutions readily become apparent.

Figure 2. Traditional and modified views of a processing pipeline.

Figure 3. Send- and reply-driven messaging.
A useful example is a traditional process pipeline, as shown in Figure 2. Data are passed from module to module after being processed. A synchronous messaging IPC would be problematic using this design—at some point, each process would block on the process ahead of it and be unable to receive an incoming message, backing up the pipeline. By redesigning the system to introduce agent processes, however, these issues are addressed. The pipeline changes into a set of server processes, while an agent becomes responsible for each element of the process as it passes through the logical, rather than the physical, pipeline. A controlling task also simplifies problems in the original design, such as a processing error that might require an element to skip some or all of the modules in the pipeline.
In fact, designers can use blocking to their advantage by intentionally blocking a process. Designers tend to envision messaging as being send driven—i.e., a client-server type relationship. It is often more useful to think of processes as being reply driven—blocked until the need for activation of the process arises. Both types of messaging systems are shown in Figure 3.
Reply-driven messaging has many uses: the examples from Figures 2 and 3 can now be combined to form a queue-and-dispatch system. In this case, a message would be sent to the master process requesting that a new element be entered into the process pipeline. If an agent process is available, it would immediately be dispatched with this information and begin processing that element. At the completion of all processing, the agent simply sends a message to the master process indicating that its task is complete and that it is again ready for work.
Is it better to use a send-driven or a reply-driven system? Most systems are a combination of the two, permitting designers to use the best mechanism to solve particular parts of the problem.
A final note about a message-passing system: since processes using message passing maintain private copies of a message, nothing prevents the message from being sent across a network as easily as it is sent within a single machine. This feature, of course, would require support from the OS.
Asynchronous Messaging. Some systems define asynchronous messaging systems in addition to queues. For example, the QNX system uses a mechanism known as a pulse to permit the originating process to asynchronously send up to one code byte and four data bytes; the receiving process then reads the message synchronously as a normal message.

Figure 4. Bidirectional communication via pulses.
When combined with synchronous messaging, pulses provide a powerful mechanism for deadlock-free bidirectional communication. As shown in Figure 4, systems can then be designed so that messages flow in a single direction and pulses are used when an event that must be propagated in the opposite direction is generated. If the message is small enough, as in the case of an analog input/output (I/O) driver that notifies a process when a new reading is available, the value may be included directly in the pulse itself. If the message is larger than can be contained in the pulse, however, then the pulse acts as a notification mechanism to let the receiving process know that the pulse originator has data for it. Upon receipt of the pulse, this process sends a message using normal synchronous messaging asking the pulse originator for the data. This type of notification mechanism is also useful for processes that cannot afford to block on a process for an arbitrary length of time, yet still must communicate with these less-trusted processes.
OS SELECTION
The final piece to be considered in software system design is the selection of the OS itself. When considering which system to select for a project, designers often assume that if the OS supports the selected software architecture, offers appropriate scheduling algorithms, and provides the necessary system services (timers, drivers, etc.), then it is sufficient for use in the product. This belief fails to consider the key elements of easy integration and reliable system operation, which are determined by the architecture of the OS itself.
Flat Architecture. While not all cpus provide an MMU, it is rare to find hardware today for a medium to large embedded system that does not contain an MMU. The reason is straightforward: an MMU, when used properly, can protect each process from typical programming errors, such as a stray pointer. Any attempt to write into the memory space of another process is caught by the MMU and prevented. The problem is that this type of protection requires support by the OS. Many systems, however, provide no support for this MMU feature— though because the systems work on a processor with an MMU it is often assumed that they do. These OSs provide a flat memory architecture.
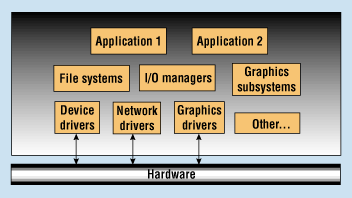
Figure 5. A flat architecture provides no memory protection.
In a flat architecture, all of the software modules, including the kernel, are folded into the same address space (see Figure 5). This gives any process the ability to write randomly into the memory space of any other process, or even the kernel. When this occurs, a system crash occurs at best, and at worst, a terminally corrupted system is created.
In addition to the potential harm resulting from operating a system with random and unknown damage, it becomes extremely difficult to debug the problem, since it is nearly impossible to determine where the damage came from or when it occurred. Even the best development tools have difficulty when presented with this type of situation; as a result, it can take days, weeks, or even months to identify and fix the problem.
Additional problems occur when the modified modules are reintegrated into the system. Whenever a module is introduced, even a slightly modified one, the entire system must be relinked, producing a unique version of the system with a distinct memory map. If the relinked system suddenly fails during testing, however, where should blame be assigned? Using Figure 5 as an example, assume a one-line code change is made in application 2 and reintegrated into the system. If the system were to fail during testing, it would be logical to blame the failure on the change in application 2. Unfortunately, this may not be accurate—the bug could easily be a stray pointer in application 1. The stray pointer might not have been recognized earlier if it were writing into an unused area of memory, since this would have no effect on system operation. The problem would only occur when the software was relinked and the memory map was changed—application 1 would then inadvertently be writing into a critical memory area. This type of problem is extremely difficult to find because designers generally do not assume that previously working code is at fault.
The real risk in a flat-architecture model is that the entire system, not just a small piece of it, becomes subject to the errors of the worst programmer who ever worked on the project. This person does not even have to work for the same company—third-party code is just as suspect since it can interact anywhere within the system. All of this takes a severe toll on product integration time (as well as on the sanity of the developers).
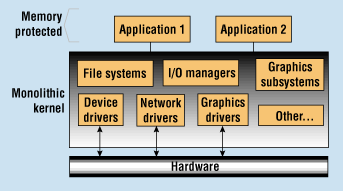
Figure 6. Monolithic architecture provides memory protection for applications.
Monolithic Architecture. In an attempt to address the problems of flat architecture, some OS vendors have adopted the monolithic architecture shown in Figure 6. A distinct improvement in this architecture is that every application module runs in its own memory-protected address space. If an application tries to overwrite memory used by another module, the MMU will trap the fault, thus allowing the developer to identify where the error occurred.
At first glance, this looks enticing: the developer is immediately notified of memory access violations and no longer has to follow blind alleys looking for subtle bugs in the code. Unfortunately, this architecture only addresses half the problem— the application modules. All of the low-level modules—file systems, protocol stacks, drivers, etc.—remain linked to the same address space as the kernel. As would occur in a flat architecture, a single memory violation in any of the system routines of the monolithic architecture will crash the system. While this is certainly an improvement over flat architecture, it fails to protect the developer from significant problems that delay integration and cause future reliability problems.

Figure 7. UPM architecture provides memory protection for all software components, including OS modules and drivers.
Universal Process Model (UPM) Architecture. UPM architecture, as shown in Figure 7, implements only core services (interprocess communications, interrupt handling, scheduling) in the kernel. With this model, optional user-level processes provide all other system services, such as file systems, device I/O, and networking. Thus, very little code that could cause the kernel to fail is running in kernel mode. This architecture also allows user-written extensions, such as new drivers, to be added to the OS without compromising kernel reliability. This type of architecture leads to faster integration in several ways:
Full use of the MMU for both system and application processes provides complete protection in the case of errant pointers; a quick diagnosis can then be made with a source-level debugger, since all processes are user level.
Because any process, including a driver, can be started and stopped dynamically, the developer can simply introduce a new process into the running system, test it, stop it, and return to the previous version for others to test with, all without rebooting the system. This makes it easy to introduce the early use of dummy processes, including drivers, that will speed development and testing since they can be replaced on the fly. Furthermore, it also permits components to be changed in the field without having to bring down the entire system.
An auxiliary process, known as a software watchdog, can be employed to aid in system development. When debugging a system that is mostly running but still has occasional problems, the software watchdog can watch for the death of a process. When this occurs, the watchdog will dump information about the errant process into a file for postmortem debugging, then restart the process so that testing can continue. The postmortem file can then be debugged off-line from the test machine to determine what caused the problem. This is superior to having only a hardware watchdog timer—which is often mandatory for safety concerns—that resets the system without explaining why the system failed. Of course, such a mechanism also makes for more reliable field operation: in addition to process-death monitoring, the watchdog can also monitor processes using methods such as periodic alive messages. It is up to the creativity of the design staff to determine the methods that best safeguard the system.
DESIGNING A SYSTEM
Having examined the design choices, it is time to design a hypothetical system—or, more accurately, a subsystem, as the detailed design of a system for an entire medical device would be too extensive to present in a single article. This example will consider a fluid-pumping system such as might be found in dialysis equipment. The example provided is not intended to describe an actual system; certain liberties have been taken to provide a simpler operational model. For example, redundant independent sensors are not employed as they normally would be where patient safety is concerned. This, along with other safety and functional factors, must be considered when designing an actual medical device, but they are not strictly necessary to demonstrate the general design principles.
For this example, the following functional requirements will be assumed:
All operator input is performed via front-panel switches.
The state of the pumping system must be displayed to the operator with an update rate of twice per second (anything beyond that usually exceeds the ability of the user to comprehend the data). Raw analog and digital I/O data must also be displayed when necessary for system troubleshooting and calibration purposes.
The system must be responsive to user-generated interrupts, such as an operator cancelling the procedure or someone pressing an emergency off switch.
Sensors will be used to monitor pump speed and fluid flow rate; if these sensors detect an abnormal condition, such as a pump speed or fluid flow rate outside of specified parameters or a high pump speed with a low flow rate, the pumping process is either adjusted or shut down.
A hardware-provided watchdog timer must be employed to stop the system if it is not regularly reset by the software.
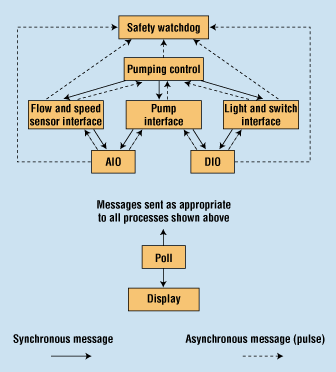
Figure 8. Design of the fluid-pumping system.
Design Proposal. A designer's first concern should be to break the problem down into a reasonable number of processes: using too many requires the developer to spend a lot of time performing needless context switches, while too few forces the merger of components that do not necessarily relate to each other. Figure 8 shows the chosen design for the fluid-pumping system, including the communication paths.
There are several reasons behind each process and its communication paths. Note that if multithreaded processes are used, each process could have a receiving thread to handle reverse-direction messages, as opposed to using pulses for this purpose; in this example, however, only single-threaded processes will be used.
Safety Layer. The safety watchdog process in the design's safety layer provides an overall health check on the system. It performs two major functions in this example: resetting the hardware watchdog timer and monitoring to ensure that other software processes are still running. While the watchdog could also perform other functions, such as comparing critical values to ensure sane system operation, in this example that will be left to other processes in the system.
The method used for checking on the health of the other processes is a simple one—regular check-in. At regular intervals, all processes are required to send a pulse to the safety watchdog process; failure to receive a pulse from any other process within the specified time period causes a corrective action to occur. Corrective actions vary depending on which process failed and the severity of that failure; the action could restart the process involved, notify the operator of an error, generate an entry in an error log, shut down the equipment, or perform any combination of the above.
The normal mode for the watchdog process would be blocked and waiting for a message or pulse to process; these messages might come from the following:
A process checking in, indicating the process is alive.
The OS, indicating the death of a process.
A timer, indicating that either a process-monitoring timeout period has elapsed or that it is time to reset the hardware watchdog timer.
The poll process.
Subsystem Control Layer. The pumping control process in the subsystem control layer is a state machine controlling the pumping subsystem. It brings the pump up to speed, monitors pump speed and flow rate, and determines how to handle out-of-boundary conditions (such as a low flow rate with a high pump speed). For this example, the pumping control process will also handle actions such as the pressing of an emergency off switch. Normally this type of control would be concentrated in a layer above the subsystem control known as the master control, which coordinates overall machine control and directs all subsystems to shut down properly. For this example, however, the pumping control subsystem will assume this responsibility. As with the safety layer, the normal mode for this process would be blocked and waiting for a message or pulse to process, with messages coming from
A device interface process (flow and speed sensor interface, pump interface, light-and-switch interface), indicating a new value or condition is available for processing. This message is delivered via a pulse. Typical types of data delivered include user actions (start or stop treatment, emergency shutdown), the current flow rate, or the rotational speed of the pump.
A timer, indicating a timeout condition or alerting that it is time to signal the safety watchdog.
The poll process.
Upon receiving a message, the pumping-control process determines the next action for the subsystem and sends out the appropriate messages to the devices (e.g., "speed up the pump," "stop the pump"). The process then waits for another message, or possibly a timer if an action was not completed on time.
It can be argued that the communication paths to the pumping control process are inverted, and that this process should never block on a message send. The reasoning here is that it is only sending to trusted processes—those known to respond quickly. More likely, however, it matters little in which direction the communication occurs as long as a single direction is chosen.
Device Interface Layer. The flow and speed sensor interface, pump interface, and light-and-switch interface—all part of the device interface layer—provide an abstraction layer for the physical hardware. Though if may be tempting to let the pumping control process directly address the analog and digital I/O devices, there are several reasons to avoid doing so, including the following:
In an actual system, the pumping control process may not be the only process to access the physical devices. By using a separate process that understands the specific operation of the physical device, a standardized hardware interface can be provided for all processes to use. This eliminates the need to encode the physical aspects of the actual hardware into each process that accesses the hardware. For example, while some types of digital devices use inverted logic to represent a "true" or "on" condition, others do not. By providing a standardized interface to these devices, developers always know that the mapped logic model represents the logic state they expect, regardless of how that logic state is physically represented on the device itself.
Devices may be made up of a combination of elements, and abstracting them permits developers to create pseudo devices. For example, in an actual system, different types of sensors may be used for a specific measurement, each with a different sensitivity range. Rather than making each process responsible for determining the proper sensor to use for any given measurement, one process has that responsibility; whenever an inquiry is made, the device layer process reports the proper current measurement regardless of the sensor or combination of sensors from which it was derived.
The I/O boards or the physical devices may eventually be replaced; by requiring each process to have an intimate knowledge of a hardware device, replacement becomes more difficult since it involves multiple software modifications. Even shared libraries require that all programs be relinked with new libraries. Failure to relink even one program, or the development of an unexpected interaction between a new shared library and one of the processes, results in erratic system operation.
When all access to a device goes through one process, it is easy to substitute dummy versions of the process for early system component testing.
Why not create one giant program that abstracts all physical devices? This could be done, but there are two reasons why it is not a good idea. The first is simplification: if all device control were integrated into a single process, it would be huge and difficult to manage, and even capable of missing time deadlines. The second reason is that by separating functionality into multiple processes, different programming teams can be assigned to implement and test each subsystem—a vital component necessary for fast system development and integration, and one that would be unavailable were the system part of one large program.
In the present example, some developers might question the pairing of the flow rate measurement and rotational speed sensor interface into a single process. While there are other methods that could be used here, this setup is beneficial: these two measurements are tightly linked, and thus it makes sense to perform routine checking (such as out-of-boundary condition checking) in a single process rather than in pumping control. The pumping control process could be notified either when an error occurred or when a sought condition is reached (e.g., "pump is at speed"). Both methods are shown in this example, and eachhas its advantages; it is left to the designer to determine the type of organization that is best for the medical device.
Again, the normal mode for these processes would be blocked and waiting for a message or pulse to process; these messages would come from
A subsystem layer process (pumping control), indicating that a value is to be read or set on a device.
A physical-hardware layer process (AIO, DIO), indicating that a new value is available for a physical device. When an I/O board needs to notify the device process of a new value, it uses a pulse that may or may not include the actual data payload.
A timer, indicating a timeout condition or indicating that it is time to signal the safety watchdog.
The poll process.
Upon receiving a message, these processes determine the appropriate action. This includes converting values to a type necessary for further operations (e.g., converting voltage to flow rate) and forwarding this value on to the next appropriate layer. Forwarding can take many forms, whether it involves responding to a message with a value or initiating a message to the proper I/O board to change or query a value.
Following are some important notes on design:
Device layer processes can be made intelligent, notifying higher-level processes only when a device value exceeds a set threshold (this threshold is unique for every requesting process) rather than notifying them of every data change, which cuts down on useless messaging traffic.
Some developers will use a pulse, without associated data, as a toggle for a digital I/O device. That is generally a bad idea; if the device layer process inadvertently loses one of the toggles, it will notify higher-level processes of an improper device state.
Even when data are sent with a pulse, these data might be old; e.g., the value may have changed before the pulse was processed. Since in general only the current value of the device is important, not the transitions that lead to this state, it is always better to query for the current value of the device.
One potential problem with sending data one element at a time occurs when dealing with pseudo devices that consist of multiple physical devices: an interpreted value might be made on both a current and an old value, as defined by the time frame under which the value is calculated. It is often better to snapshot the entire device within a set time frame and base calculated values on those results.
Physical Hardware Layer. The AIO and DIO processes of the physical hardware layer, which control the actual I/O boards, constitute the physical hardware driver layer. A separate process is used for each type of board being used, permitting hardware to be easily replaced since the interface to external programs remains the same. Multiple boards of identical type can be driven by one driver process.
As with the previous process formats, the normal mode for these processes would be blocked and waiting for a message or pulse to process; these messages might come from the following locations:
A device interface process (flow and speed sensor interface, pump interface, light-and-switch interface), indicating that an I/O port is to be read or set.
A timer if the devices are running in a polled mode (rather than a hardware-interrupt-driven mode)—this is both hardware and application dependent. Timer notification will also be received when it is time to notify the safety watchdog.
The poll process.
Upon receiving a message, the process would determine the appropriate action; this would include beginning a data scan, replying with the current port value, or initiating a pulse to another process indicating that data is ready.
Display Layer. The display and poll processes, which are part of the display layer, are responsible for displaying information about the system on the user interface. Why are two processes necessary? Normally, one would expect that information to be displayed would be sent to the display process by the appropriate responsible process—e.g., the pumping control process would send information about whether it has begun pumping, or that the pump is up to speed, etc.
The problem is with the physical devices themselves—these are constantly changing values (at least in the case of analog I/O values) that need to be displayed twice per second, as specified by the pump's functional requirements. While the physical device interfaces could constantly send this information to the display process, that would be wasteful if the screen currently being displayed does not show those values. To solve this problem, the information is only polled for when it is being displayed on the screen. If the display process does this directly, however, it will not be ready to receive a message from another process (potentially in another subsystem) that needs to update the display—possibly causing that process to miss a critical time deadline (display is considered a fast, trusted process). The solution is to introduce the poll process, which acts as an agent for the display process.
When the display system starts operation, the display process blocks, waiting for a message to process. The poll process then starts, sending a message to the display process indicating that it is ready for operation. By not replying to the poll process, the display process prevents the poll process from further execution and retains control of the polling process. Display then sets a repeating timer that triggers at 0.5-second intervals. When the timer triggers, the display process replies to the poll process with specific instructions as to which processes to query for the real-time data currently being displayed on the screen. The poll process then queries those specific processes for the real-time data, forwards this information back to the display process, and waits for the next poll cycle.
The pumping control and safety watchdog processes need not be polled; information in these processes rarely changes and it is wasteful to constantly poll them for the same data. Instead, these processes can send changes directly to the display process when the data changes. The only concern is with the safety watchdog: if the display process takes too much time to process the message, the resetting of the hardware watchdog timer might get delayed, causing an inadvertent system shutdown. This is probably not a serious consideration since the display process is a fast, trusted process, but this possibility can nevertheless be prevented with the introduction of another pulse. Using this additional pulse, the display process is notified of a value change by a pulse sent by the safety watchdog; upon receipt, the display process simply directs the poll process to seek the new value on its next data-gathering pass.
It should be noted that this is not the only design method that could be used for this system—it is merely a valid possibility. Other IPC mechanisms such as a queue could be used, but with the trade-off of additional system overhead. Shared memory would also work in some areas. For example, device values read from the I/O boards and those calculated by the device processes could have been written to shared memory since these are write-once, read-multiple items. Of course, this only applies if they are single-word values (or less); anything larger would require the use of a data-synchronization mechanism to prevent possible concurrency problems. Shared memory might improve the performance somewhat, but probably not a lot— messages would still have to be generated to notify processes when data is available or has changed; otherwise, the processes would have to block on a semaphore (effectively the same as blocking on a message), or poll for changes (tying up the cpu).
CONCLUSION
Architecture, both in the software design and in the underlying operating system, is a differentiating factor for faster system development. Through the use of a process-oriented architecture coupled with a messaging IPC, programming teams working in parallel can develop a system where each component is tested in isolation and then quickly integrated into the completed product. This system also provides for a more flexible architecture, as individual components can be easily replaced as requirements change during system development. Furthermore, by coupling this type of architecture with an OS that provides full MMU support, the developer is assured that unintended data interactions cannot occur—problems such as a stray pointer will immediately be caught by the MMU and easily debugged.
The result is a faster time to market because manufacturers will not be fighting the typical system integration nightmares. Later, when the system is deployed in the field, these same mechanisms will provide for extremely reliable system operation, particularly when coupled with a software watchdog. Designing with this type of architecture also benefits future projects: each component need only be developed once, since any process can be reused in another project with the knowledge that it will act in exactly the same manner.
With development time being such a limited commodity to-day, wasting it using the wrong software architecture is an error that can be avoided. The proper design choices make this possible and yield benefits throughout the lifetime of the project.
BIBLIOGRAPHY
Fletcher-Haynes, P. "Rx:QNX—COBE Remedies the High Cost of Blood Collection," QNXnews 11, no. 7 (1998): 7—12.
Isensee, G. "Stress-Free ECG—QNX Gives Burdick's Quest a Running Start," QNXnews 11, no. 2 (1997): 7—12.
Leroux, PN. The New Business Imperative: Achieving Shorter Development Cycles while Improving Product Quality. (Kanata, ON, Canada: Whitepaper, 1999).
Stevens, WR. UNIX Network Programming. (Englewood Cliffs, NJ: Prentice-Hall, 1990).
Stewart, DB. "30 Pitfalls for Real-Time Software Developers, Part 1," Embedded Systems Programming 12, no. 11, (1999): 32—41.
Stewart, DB. "More Pitfalls for Real-Time Software Developers," Embedded Systems Programming 12, no. 12, (1999): 74—86.
Tanenbaum, AS. Operating Systems—Design and Implementation. (Englewood Cliffs, NJ: Prentice-Hall, 1987).
Jeffrey Schaffer is a senior applications engineer at the Westlake Village, CA, office of QNX Software Systems Inc., an operating systems vendor headquartered in the Ottawa, Canada area. He has more than 20 years of experience working with operating systems, database internals, and system design.
Return to the MDDI May table of contents | Return to the MDDI home page
Copyright ©2000 Medical Device & Diagnostic Industry
You May Also Like


