Apr 18, 2024
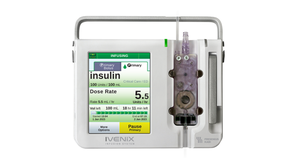
Fresenius Kabi USA Infusion Pump Software Recall Declared Class I
Abbott Has a Powerful Product Lineup in the Chamber
Ensuring Today’s Innovations Do Not Become Tomorrow’s Problems
Vivasure Opens up about Securing a Top Spot in Vessel Closure Market
.svg?width=700&auto=webp&quality=80&disable=upscale)


























.png")