thumbnail
Product DevelopmentProven Insights for Efficient Medical Device Design & DevelopmentPractical Insights for Medical Device Design & Development
A look at the tools and strategies you need for strong product development.



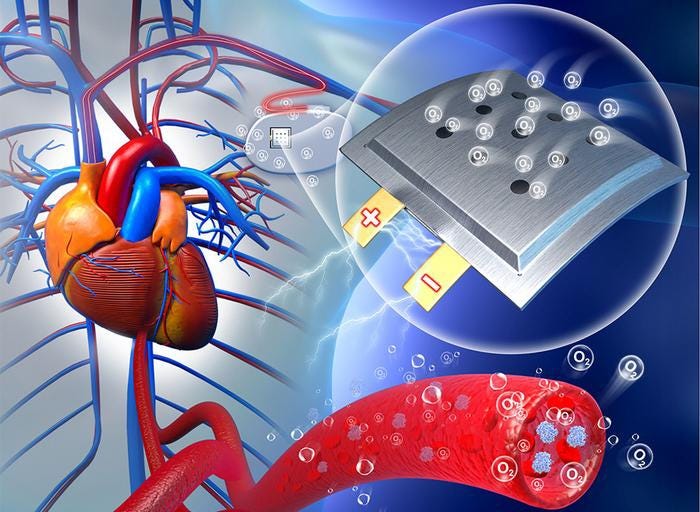

.png?width=700&auto=webp&quality=80&disable=upscale)


![Featured Image] 230916SF73.jpg](https://eu-images.contentstack.com/v3/assets/blt14ac89070d5e4751/blt381af30a9066bd0b/655b99d3323a8f040a9ee156/Featured_Image_230916SF73.jpg?width=300&auto=webp&quality=80&disable=upscale "Featured Image] 230916SF73.jpg")

























.jpg")
.jpg")





Editors' Choice


Sign up for the QMED & MD+DI Daily newsletter.